はじめに
この記事では、Burstコンパイラについての概要の説明と、実際に簡単な計算を行うコードをBurstコンパイラによって最適化しつつ、SIMD化の挙動について確かめてみます。
また、実機でパフォーマンスを計測して、どの程度高速化するのかについても確かめてみます。
検証環境は下記のとおりです。
- Unity 2020.3.32f1
- Burst 1.6.5
- Performance testing API 2.8.0-preview
- Android Pixel 4a
BurstとSIMD化について
https://blog.unity.com/ja/technology/enhancing-mobile-performance-with-the-burst-compiler
https://www.youtube.com/watch?v=rvBpUPFN5_I
BurstはDOTS(データ指向技術スタック)向けの事前コンパイラー技術です。
Unity通常のアプリケーション、特にil2cppがスクリプトバックエンドなアプリケーションではC#で書かれたコードをil2cppという技術でC++に変換します。
一方Burstでは、C#(厳密にはC#のサブセット言語であるHPC#)を.NET Assemblyを経由してLLVMというコンパイラー基盤の中間構文であるIRに変換し、それを最適化します。 この最適化の一環で利用できるところはSIMD命令を用いたりCPUアーキテクチャごとの最適化などを行って、通常のil2cppで生成される命令よりも高速な命令を生成します。
SIMDは(Single Instruction/Multiple Data)の略で、1命令で複数データをまとめて処理するような命令を指します。 この命令を積極的に使うことでデータの処理を並列に実行でき、それにより高速化が期待できます。
Burstを試してみる
今回はとりあえず動かすところを確かめたいので、早速Burstを触ってみます。
ピュアなC#実装とパフォーマンス計測について
下記のような、与えられた配列の要素を2乗して出力配列に格納するという実装を例に、これをBurst(+Job System)により高速化してみます。
private static readonly int s_Size = 1048576;
private float[] InputArray;
private float[] OutputArray;
[OneTimeSetUp]
public void Setup()
{
// 配列の確保は1回だけやる
InputArray = new float[s_Size];
OutputArray = new float[s_Size];
}
[Test, Performance]
public void TestBaseline()
{
Measure
.SetUp(() =>
{
// 配列の初期化
for (int i = 0; i < InputArray.Length; i++)
{
InputArray[i] = 1.0f * i;
}
})
.Method(() =>
{
for (var i = 0; i < InputArray.Length; i++)
{
// 要素を2乗して出力配列に代入
OutputArray[i] = InputArray[i] * InputArray[i];
}
})
.Run();
}ちなみに Performance 属性はPerformance testing API が提供する属性で、上記のようにテストコードを書くと、このコードをエディターやiOS/Android実機上で簡単にパフォーマンスチェックできます。
この記事ではPerformance testing APIについては最低限の使い方の紹介にとどめますが、詳細はこちらの記事を参考にしてみてください。
Performance testing APIを用いると、テストを実行するようなノリでそのまま実機上でのパフォーマンス計測が可能です。
Burst実装
下記に上記のベースライン実装のBurst実装を示します。
[BurstCompile(CompileSynchronously = true)]
private struct MyBurstJob : IJob
{
[ReadOnly] public NativeArray<float> Input;
[WriteOnly] public NativeArray<float> Output;
public void Execute()
{
for (int i = 0; i < Input.Length; i++)
{
Output[i] = Input[i] * Input[i];
}
}
}ほぼジョブ実装しているだけで、違いは BurstCompile 属性を指定している点です。基本的にはジョブ実装に BurstCompile を指定することで、そのジョブがBurstコンパイラにより最適化されます。
最適化されたコードは、(各プラットフォームごとの機械語ではありますが)Burst Inspectorから確認できます。Burst Inspectorは「メニュー > Jobs > Burst > Open Inspector…」で開けます。
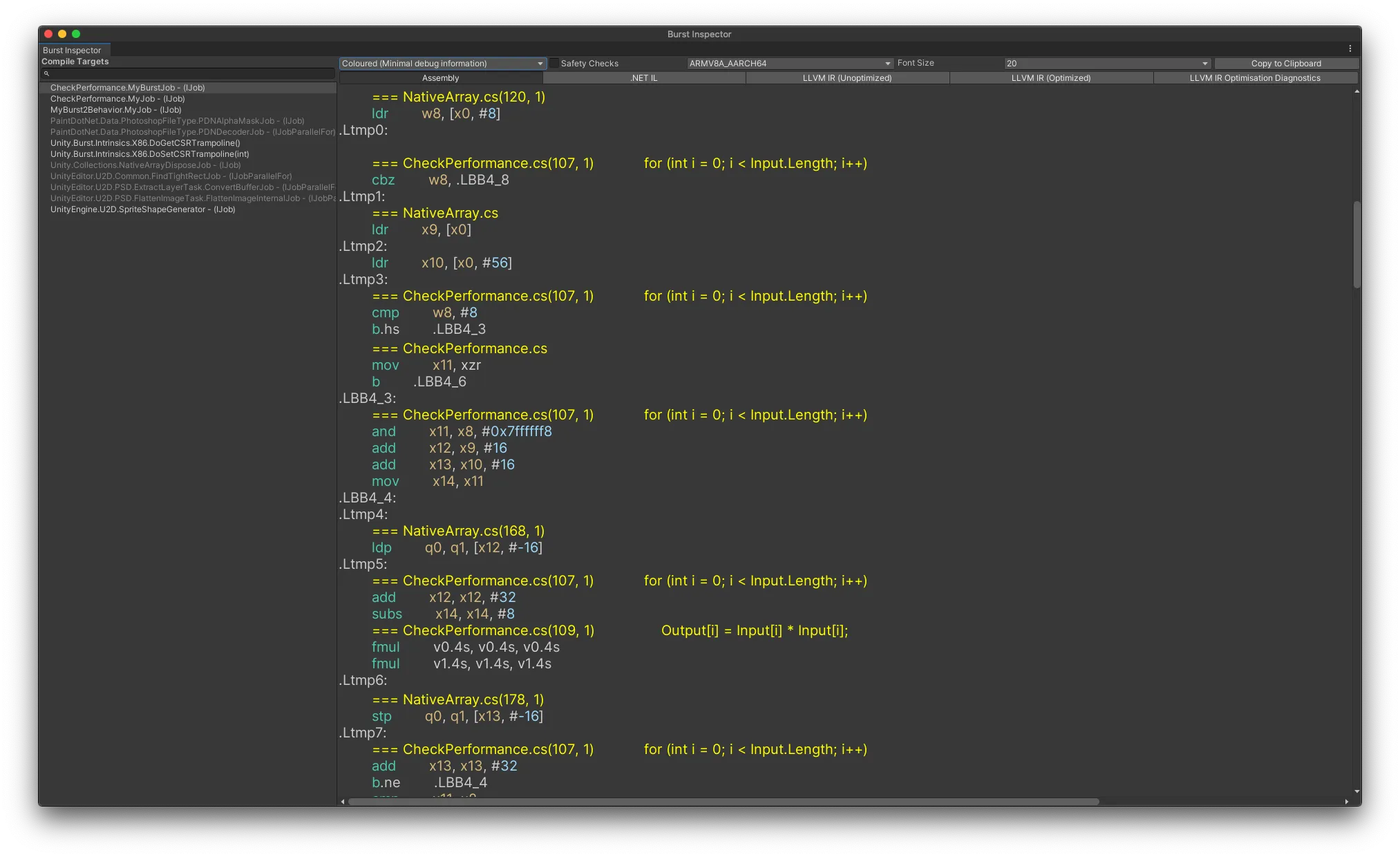
Burst InspectorでARMV8A_AARCH64向けに吐き出されたコードを確認してみます。特に下記の部分の fmul なのですが、SIMD命令が利用されていることが確認できます。
.Ltmp7:
.loc 3 107 0 // CheckPerformance.cs:107:0
add x12, x12, #32 // =32
subs x14, x14, #8 // =8
.loc 3 109 0 // CheckPerformance.cs:109:0
fmul v0.4s, v0.4s, v0.4s
fmul v1.4s, v1.4s, v1.4sパフォーマンス検証
ピュアなC#実装とジョブシステムによる実装、ジョブシステム+Burst実装の3実装で比較します。計測はPixel 4aで行いました。配列の初期化は計測に含めないものとします。
ビルド時のパラメータは下記のとおりです。
- Scripting Backend: IL2CPP
- C++ Compiler Configuration: Release
- Burst AOT Settings > Optimize For: Performance
| 実装 | 中央値 (ms) | 最小 (ms) | 最大 (ms) | 標準偏差 |
|---|---|---|---|---|
| ピュアC# | 5.26 | 5.25 | 5.30 | 0.02 |
| ジョブシステム | 1.70 | 1.69 | 1.71 | 0.00 |
| ジョブシステム+Burst | 0.98 | 0.98 | 0.99 | 0.00 |
ジョブシステム+BurstがピュアなC#実装と比べて約5倍ほど高速であることを確認できました。